操作説明戻る
[オプション画面]
[比較対象] [比較方法] [テキスト比較] [処理方法] [出力内容] [システム]
メイン画面の[同一ファイル検索]、[ファイルとフォルダーの検索]、[1ファイルの比較]で使用します。
*1 [同一ファイル検索]で使用する項目
*2 [ファイルとフォルダーの検索]で使用する項目
*3 [1ファイルの比較]で使用する項目
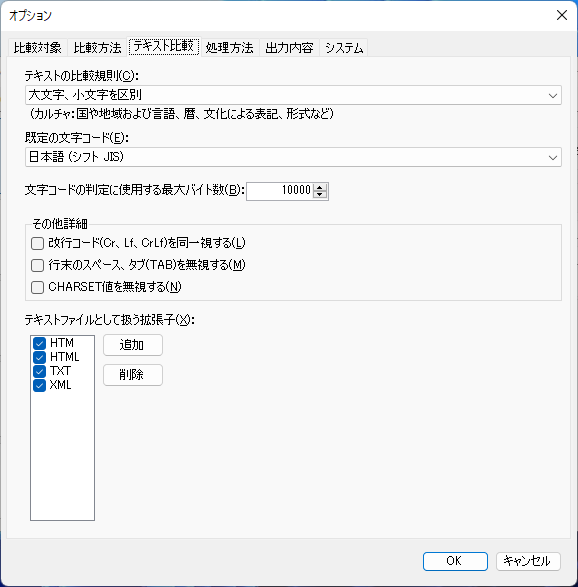
[テキストの比較規則(C)] *1 *2 *3
テキストの比較規則を下に示す内容から選択します。
内容 大文字、小文字を区別(使用環境のロケール情報(カルチャ)を使用) 大文字、小文字を区別しない(使用環境のロケール情報(カルチャ)を使用) 大文字、小文字を区別(使用環境のロケール情報(カルチャ)に依存しないカルチャを使用) 大文字、小文字を区別しない(使用環境のロケール情報(カルチャ)に依存しないカルチャを使用) 大文字、小文字を区別 大文字、小文字を区別しない [既定の文字コード(E)] *1 *2 *3
テキスト変換時に文字コードが不明な場合に使用する文字コードを指定します。
[文字コードの判定に使用する最大バイト数(B)] *1 *2 *3
文字コードの調査を行うときに使用するデータの最大バイト数を指定します。
[その他詳細] *1
[改行コード(Cr、Lf、CrLf)を同一視する(L)]
ONの場合 ・・・ 異なる改行コードも同じコードとして比較します。 OFFの場合 ・・・ 異なる改行コードは別々のコードとして比較します。 [行末のスペース、タブ(TAB)を無視する(M)]
ONの場合 ・・・ 行末のスペース(半角、全角)、タブ(TAB)は無いものとして比較します。 OFFの場合 ・・・ 行末のスペース(半角、全角)、タブ(TAB)も比較します。 [CHARSET値を無視する(N)]
ONの場合 ・・・ HTML文のCharset値、XML文のencoding値は無いものとして比較します。 OFFの場合 ・・・ HTML文のCharset値、XML文のencoding値も比較します。 [テキストファイルとして扱う拡張子(X)] *1 *2
指定しているファイルの拡張子を テキストファイルとして扱います。
[拡張子の一覧]チェックが付いている拡張子をテキストファイルとして扱います。
<追加>
[拡張子の一覧]にファイルの拡張子を追加します。
※追加したファイルの拡張子は即座に反映されます。<削除(D)>
[拡張子の一覧]で選択しているファイルの拡張子を削除します。
※削除したファイルの拡張子は即座に反映されます。
<OK>
変更内容を保存し、前の画面に戻ります。
<キャンセル>
変更内容を保存せずに、前の画面に戻ります。
[管理ツール]でユーザー名、パスワードが登録されている場合
[オプション]画面を表示する前に、ユーザー名とパスワードの確認を行います。
ユーザー名、パスワードが一致しない場合は、ロック状態で[オプション]画面を開きます。
[管理オプションロック設定]により変更できる項目が制限される場合があります。